
Преобразовать речь в текст (speech to text) легко с помощью бесплатной модели автоматического распознавания речи Whisper от компании OpenAI, создателя ChatGPT. В этой статье распознаем речь на русском и на английском языке. Распознаем речь как уже записанную в аудио файл, так и аудиопоток (живой звук) с микрофона. Работать будем в Debian. Погнали!
Содержание
скрыть
Установка Whisper
Актуализируем установленные версии пакетов Debian:
apt update && apt upgrade -yУстанавливаем Python, библиотеку PyTorch для Python, менеджер пакетов Pip для Python, пакет Venv для виртуальных окружений в Python и пакет инструментов для работы с аудио и видео FFmpeg:
apt install python3 python3-torch python3-pip python3-venv ffmpegПроверяем версию установленного Python:
python3 --versionДожна быть версия не менее Python 3.9.9.
Начиная с Python 3.12, а в некоторых сборках с Python 3.11, попытка установить пакет с помощью команды pip install не увенчается успехом:
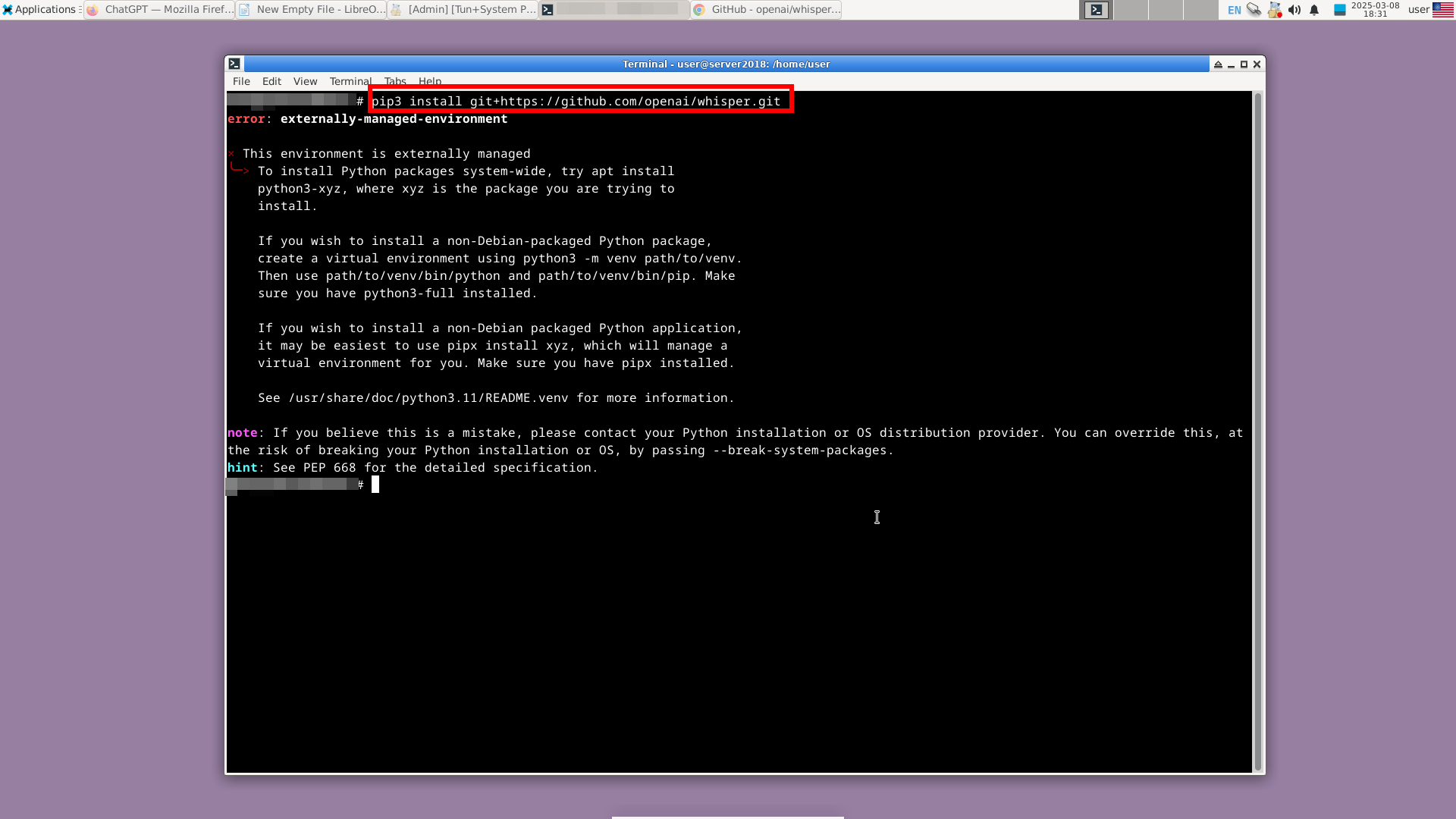
Ниже строки «error: externally-managed-environment» имеются разъяснения, что Python-пакет можно установить командой apt. Если же Python-пакет желаете ставить командой pip install, то нужно предварительно создать виртуальное окружение Python. Это все сделано, чтобы избежать конфликтов между пакетами, установленными через apt и pip.
Под обычным пользователем (не root) cоздаем виртуальное окружение Python с именем whisper_env:
python3 -m venv whisper_envАктивируем виртуальное окружение whisper_env:
source whisper_env/bin/activateКогда понадобится выйти из виртуального окружения:
deactivateКогда понадобится удалить виртуальное окружение whisper_env:
rm -rf whisper_envВ виртуальном окружении устанавливаем самую свежую версию Whisper от OpenAI:
pip install git+https://github.com/openai/whisper.git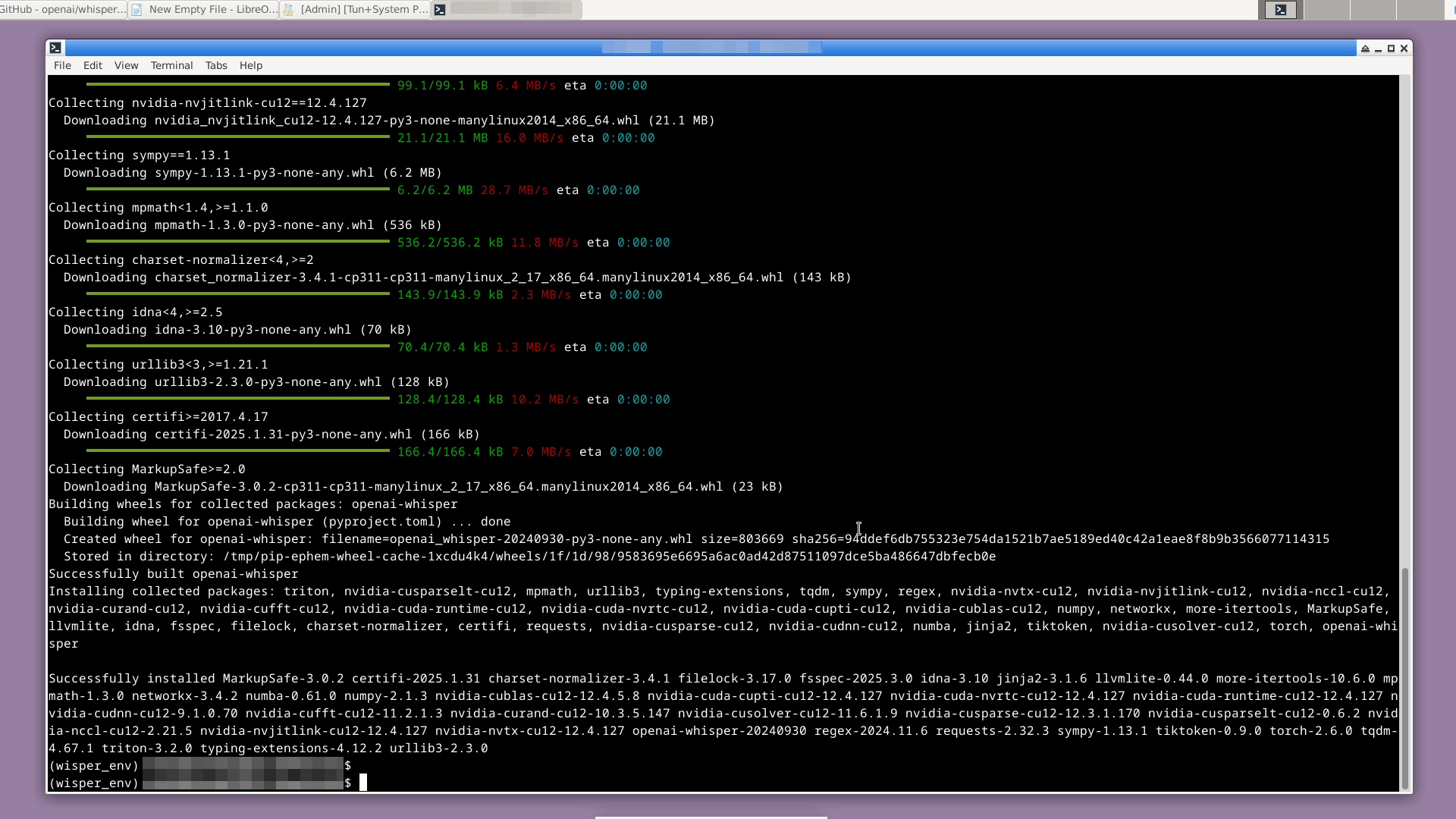
Whisper и необходимые ему для работы пакеты успешно установлены.
Если понадобится обновить Whisper:
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.gitSpeech to text для аудиофайла
Whisper поддерживает аудиофайлы в следующих форматах: mp3, wav, m4a, flac, ogg, webm.
Для преобразования речи в текст (speech to text) запустим Whisper в командной строке, например, для аудиофайла на английском языке:
whisper /home/user/test.mp3 --model base --language Englishгде /home/user/test.mp3 – путь к аудиофайлу, который нужно обработать.
--model base – выбор модели base (средняя точность, хорошая скорость). Всего доступно шесть моделей, различающихся по размеру, скорости и точности: tiny, base, small, medium, large, turbo.
--language English – явное указание языка речи. Без явного указания языка Whisper сам определит язык.
Whisper обрабатывает аудиофайл и выводит распознанный текст с временными метками в терминал:
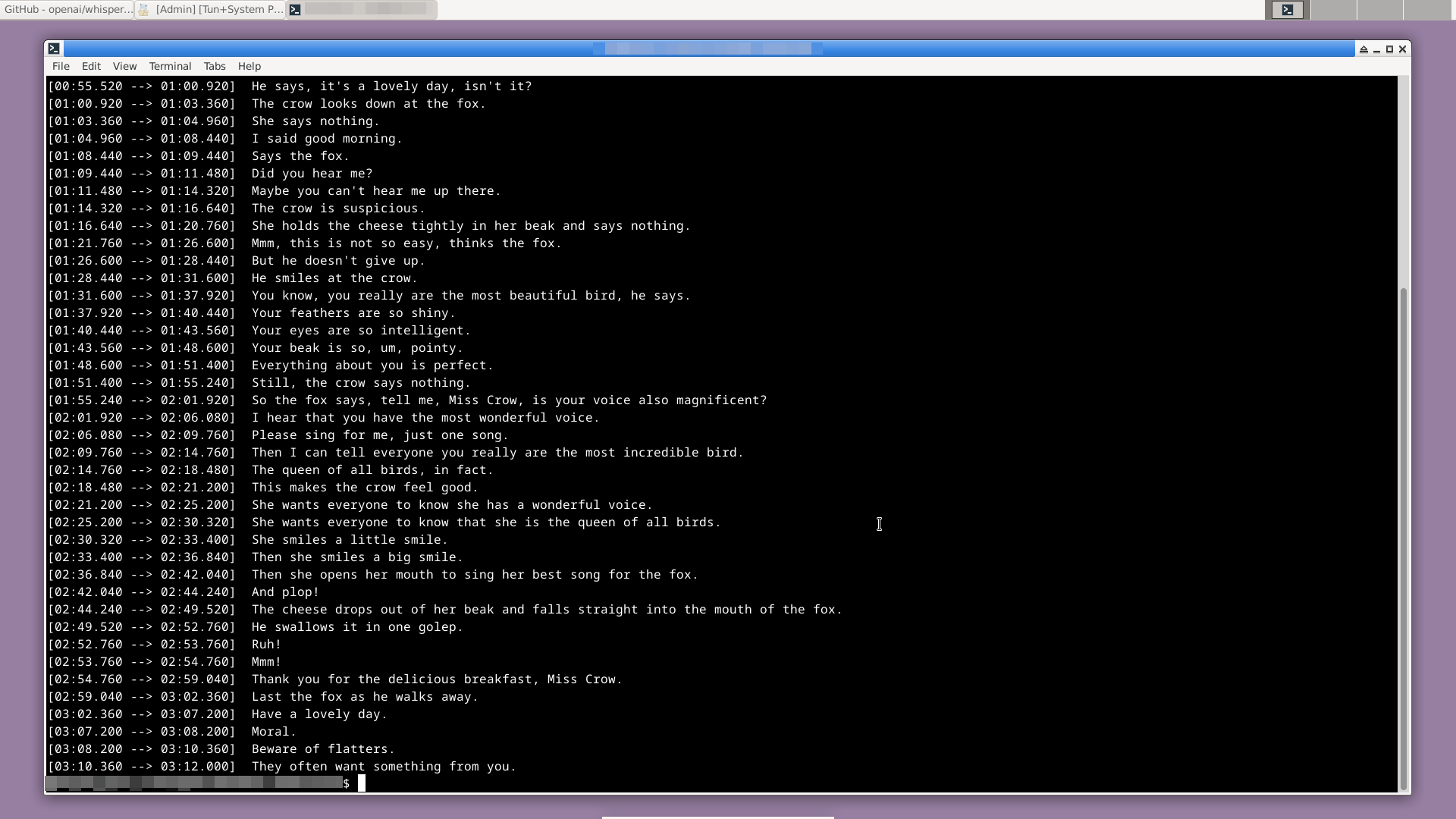
Кроме того, Whisper создает пять файлов с расширениями:
- .txt — просто текст без временных меток;
- .srt — формат субтитров с таймкодами, например, для видео на YouTube;
- .vtt — формат субтитров, используемый в HTML5-видеоплеерах;
- .json — структурированные данные с временными метками для программного анализа;
- .tsv — тект и время в табличной форме.
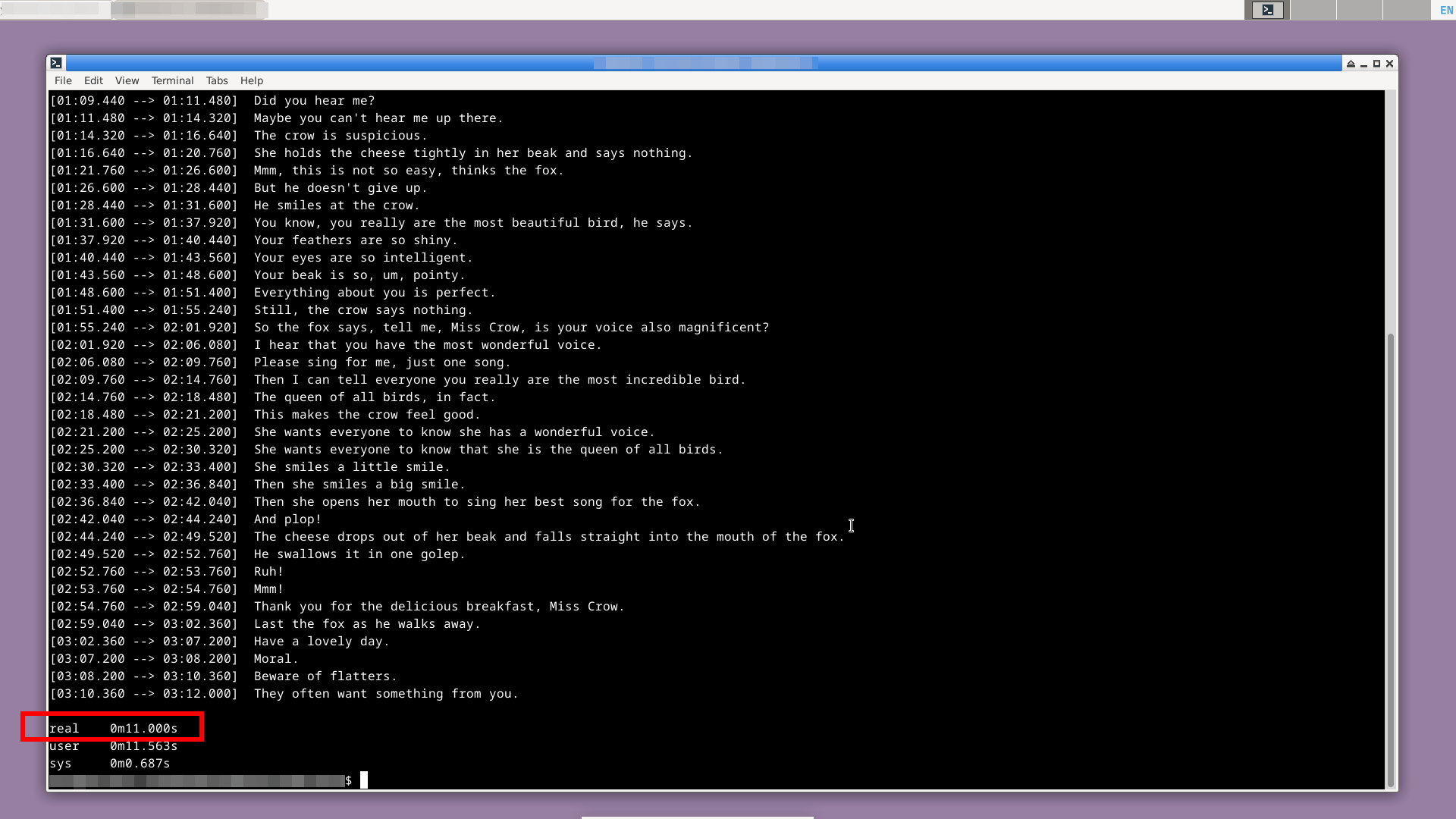
Чтобы обработать аудиофайл и узнать время, которое понадобилось Whisper для обработки этого файла:
time whisper /home/user/test.mp3 --model base --language EnglishНапример, mp3 аудиофайл на английском языке, длительностью 3:18 минут, был обработан с помощью модели base за 11 секунд.
Вот пример Speech to text обработки с помощью Whisper и модели base для mp3 аудиофайла на русском языке длительностью 12:22 минут. Время обработки — 1 минута и 2 секунды:
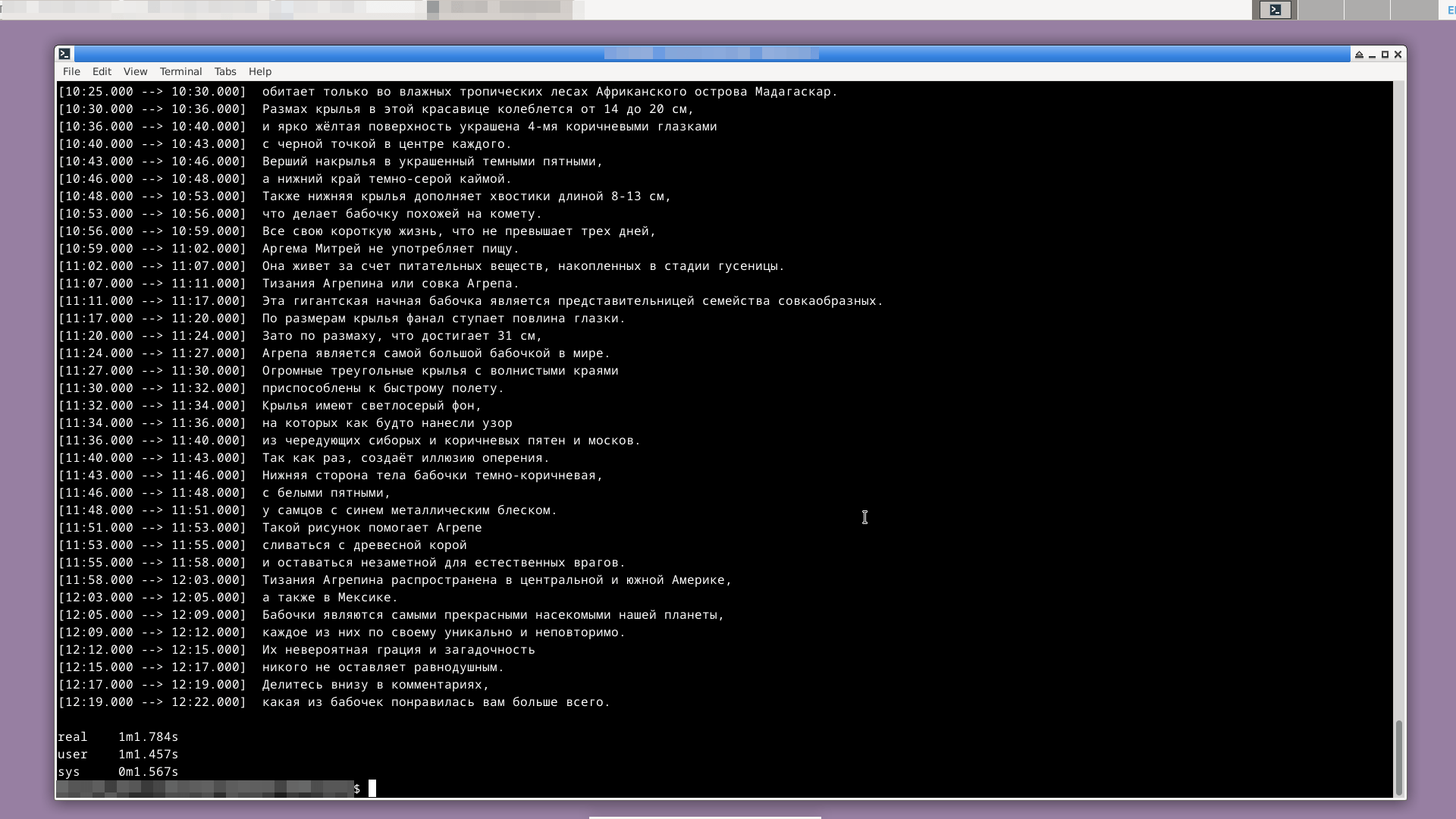
Модель base быстрая, но делает ошибки. Я обнаружила ошибки в распознанном тексте и на английском языке, и на русском. Следующая по точности модель small уже эти ошибки не сделала. Так что, экспериментируйте!
Speech to text для аудиопотока с микрофона
Источник звука по умолчанию
Проверяем, какое устройство в данный момент установлено по умолчанию как источник звука:
pactl info | grep "Default Source"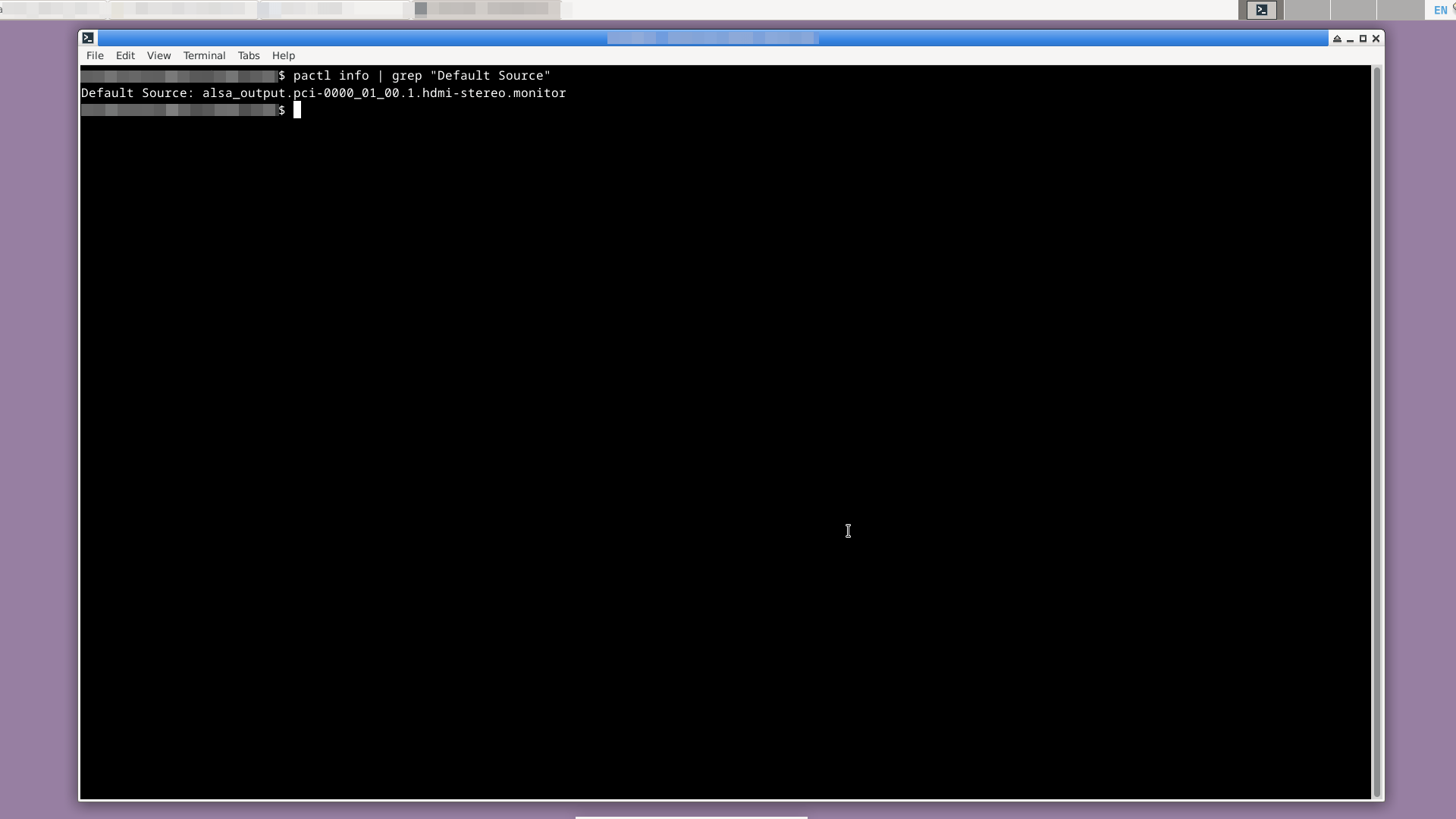
Если это не микрофон, как у меня, то смотрим, какие вообще есть устройства — источники звуков:
pactl list sources short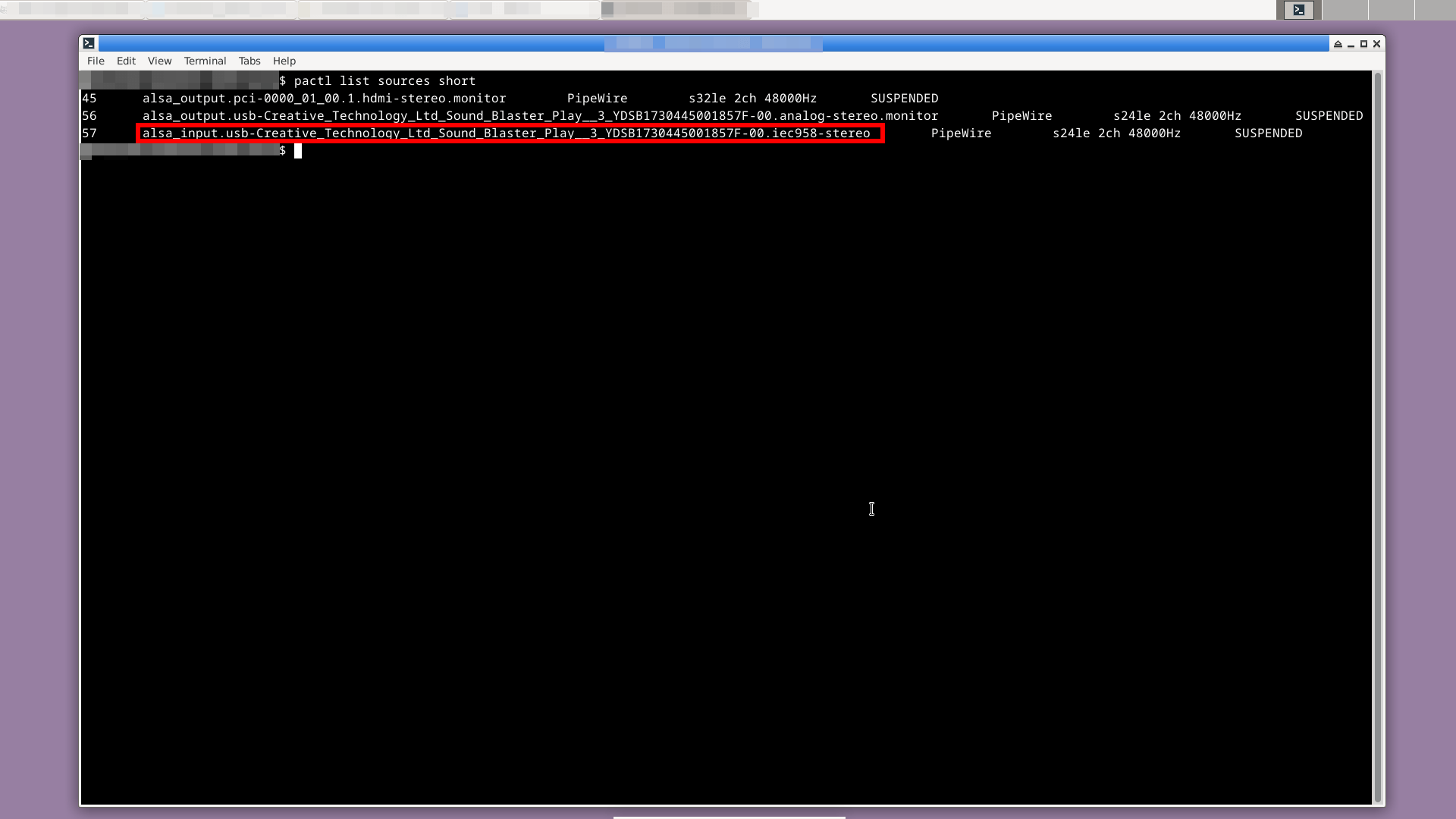
Устанавливаем микрофон как устройство — источник звука по умолчанию:
pactl set-default-source <имя_устройства>В моем случае это будет команда:
pactl set-default-source alsa_input.usb-Creative_Technology_Ltd_Sound_Blaster_Play__3_YDSB1730445001857F-00.iec958-stereoПроверка микрофона
Проверить работоспособность микрофона можно, например, записав короткий аудиофайл, а затем прослушав его. Команда на запись аудиофайла:
arecord -f cd -d 5 test-mic.wavгде -f cd — качество записи 44100 Гц, 16 бит, стерео;
-d 5 — длительность записи 5 секунд;
test-mic.wav — имя выходного аудиофайла.
Прослушаем аудиофайл test-mic.wav:
aplay test-mic.wavPython программа — speech to text для аудиопотока с микрофона
Устанавливаем Python-библиотеку PyAudio для работы с микрофоном:
pip install pyaudioДля преобразования Speech to text для аудиопотока с микрофона напишем небольшую программу на Python и назовем ее, например, streaming_speech_recognition.py:
import whisper
import pyaudio
import numpy as np
import torch
# Determine whether to use GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device.upper()} for computations")
# Load the Whisper model
model = whisper.load_model("small", device=device)
# Audio stream settings
FORMAT = pyaudio.paInt16 # 16-bit audio
CHANNELS = 1 # Mono sound
RATE = 16000 # Sample rate
CHUNK = 1024 # Buffer size
# Initialize PyAudio
audio = pyaudio.PyAudio()
# Open a stream for recording from the microphone
stream = audio.open(format=FORMAT, channels=CHANNELS, rate=RATE,
input=True, frames_per_buffer=CHUNK)
print("Speak... (Press Ctrl+C to exit)")
try:
while True:
frames = []
# Record audio for ~5 seconds (can be changed)
for _ in range(int(RATE / CHUNK * 5)): # 5 seconds of audio
data = stream.read(CHUNK)
frames.append(np.frombuffer(data, dtype=np.int16))
# Convert data to a NumPy array and normalize
audio_data = np.concatenate(frames, axis=0).astype(np.float32) / 32768.0
# Transcribe speech using Whisper
result = model.transcribe(audio_data, language="en", fp16=False) # fp16=False for CPU
print("Recognized text:", result["text"])
except KeyboardInterrupt:
print("\nStopping the program...")
stream.stop_stream()
stream.close()
audio.terminate()Как это работает?
Если в двух словах, то программа streaming_speech_recognition.py в реальном времени пишет звук с микрофона, обрабатывает его и передает в модель Whisper для распознавания речи. Распознанная речь выводится в терминал.
Если подробнее описать, то получается следующая последовательность действий:
- Определение устройства для вычислений модели Whisper: GPU или CPU. Если подходящего GPU не обнаружно, используется CPU.
- Загрузка модели small Whisper. Можно экспериментировать и с другими моделями: tiny, base, medium, large, turbo.
- Настройки аудиопотока:
FORMAT = pyaudio.paInt16— 16-битное аудио (стандартный формат);CHANNELS = 1— один канал, как у большинства микрофонов;RATE = 16000— частота дискретизации (обычно 16 кГц для речи);CHUNK = 1024— размер одного пакета данных, считываемых с микрофона. - Открытие потока
stream, который захватывает звук с микрофона. - Запуск бесконечного цикла
while True, в котором:- звук с микрофона считывается кусками (
stream.read(CHUNK)) и складывается вframes; - цикл
for _ in range(...)повторяетstream.read(CHUNK)столько раз, чтобы записать 5 секунд аудио. Можно уменьшить задержку, например, записывая 1 секунду вместо 5; - после записи 5 секунд аудио данные преобразуются в numpy массив и нормализуются для передачи в Whisper;
- Whisper обрабатывает звук, явное указание языка
language="en"ускоряет обработку,fp16=False— отключает Float16, если используется CPU; - распознанная речь выводится в терминал.
- звук с микрофона считывается кусками (
- Завершение программы, если пользователь нажимает Ctrl+C.
Запуск Python программы
Для запуска программы streaming_speech_recognition.py:
python3 streaming_speech_recognition.pyПри первом запуске программы скачается small модель Whisper, размер которой ~460 MB. Для сравнения, размер base модели Whisper ~140 MB.
Рядом с микрофоном я проиграла test.mp3 — аудиофайл на английском языке, который тестировался с Whisper самый первый:
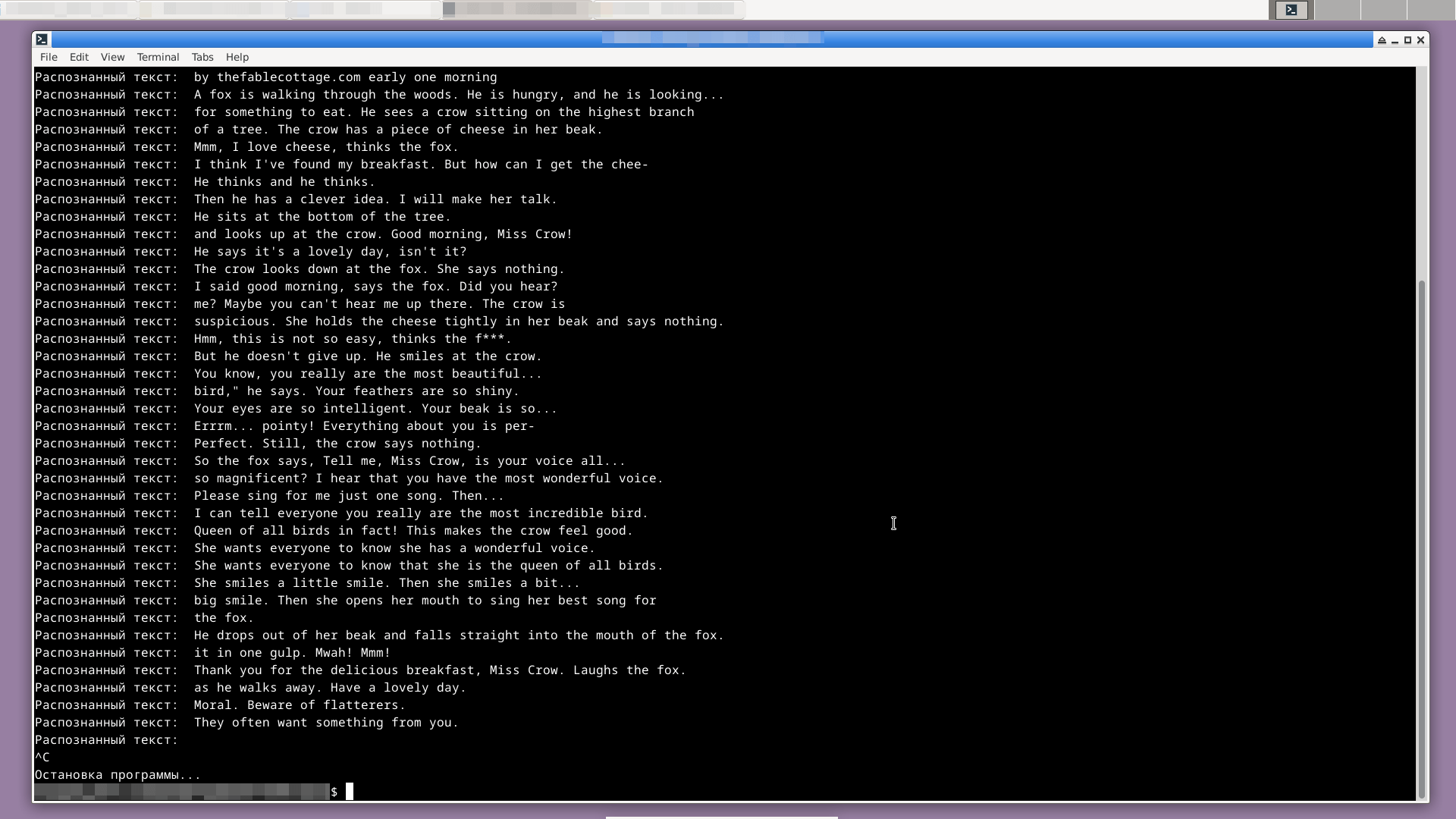
Я в восторге от результата!
Вывод
Напишите в комментариях, как Speed to text можно использовать в реальной жизни. Будет интересно!
Комментарии