
Я готовлюсь к интервью на английском языке. Поэтому бесплатный, оффлайн переводчик в реальном времени с английского языка на русский всего того, что происходит на интервью, мне очень пригодится. Давайте делать!
Что будем делать?
Будем делать бесплатный, оффлайн и в реальном времени переводчик, который будет распознавать речь на английском языке, переводить на русский язык и синтезированным голосом вещать в Bluetooth наушник в ухе.
Бесплатный — поскольку в России все меньше возможностей оплатить иностранные платные сервисы, да и не хотелось бы зависеть от их доступности и нагруженности.
Оффлайн — чтобы не зависеть от качества и доступности Интернета.
В реальном времени — поскольку требуется перевод «живой» беседы на интервью.
Операционная система и «железо»
Операционная система: Debian 12. А «железо» — приведу характеристики моего:
CPU: Intel(R) Xeon(R) CPU E3-1275 v6 @ 3.80GHz
Кол-во ядер CPU: 8
RAM: 32 Gb
Disk: 450 Gb SSD
GPU: NVIDIA GeForce RTX 4060 Ti
GPU MEM: 16 Gb
Тут хотелось бы напомнить, что в Интернете существует большое количество предложений аренды сервера с GPU. А как настроить удаленный рабочий стол с пробросом локального микрофона и динамика на сервер читайте в статье: «Удаленный рабочий стол со звуком, микрофоном, передачей файлов и USB устройствами«.
Установка Python и необходимых пакетов
Устанавливаем Python, менеджер пакетов Pip для Python, пакет Venv для виртуальных окружений в Python и набор инструментов для работы с аудио и видео FFmpeg:
apt install python3 python3-pip python3-venv ffmpegПод обычным пользователем (не root) cоздаем виртуальное окружение Python с именем venv:
python3 -m venv venvАктивируем виртуальное окружение venv:
source venv/bin/activateОбновляем версию Pip:
pip install --upgrade pipБудем устанавливать Python-библиотеку PyTorch с поддержкой GPU (Graphics Processing Unit) и CUDA (Compute Unified Device Architecture). Это позволит улучшить производительность за счет использования ресурсов видеокарты.
Проверить, что NVIDIA GPU поддерживает CUDA, можно на официальном сайте NVIDIA: https://developer.nvidia.com/cuda-gpus.
Узнаем версию CUDA:
nvidia-smi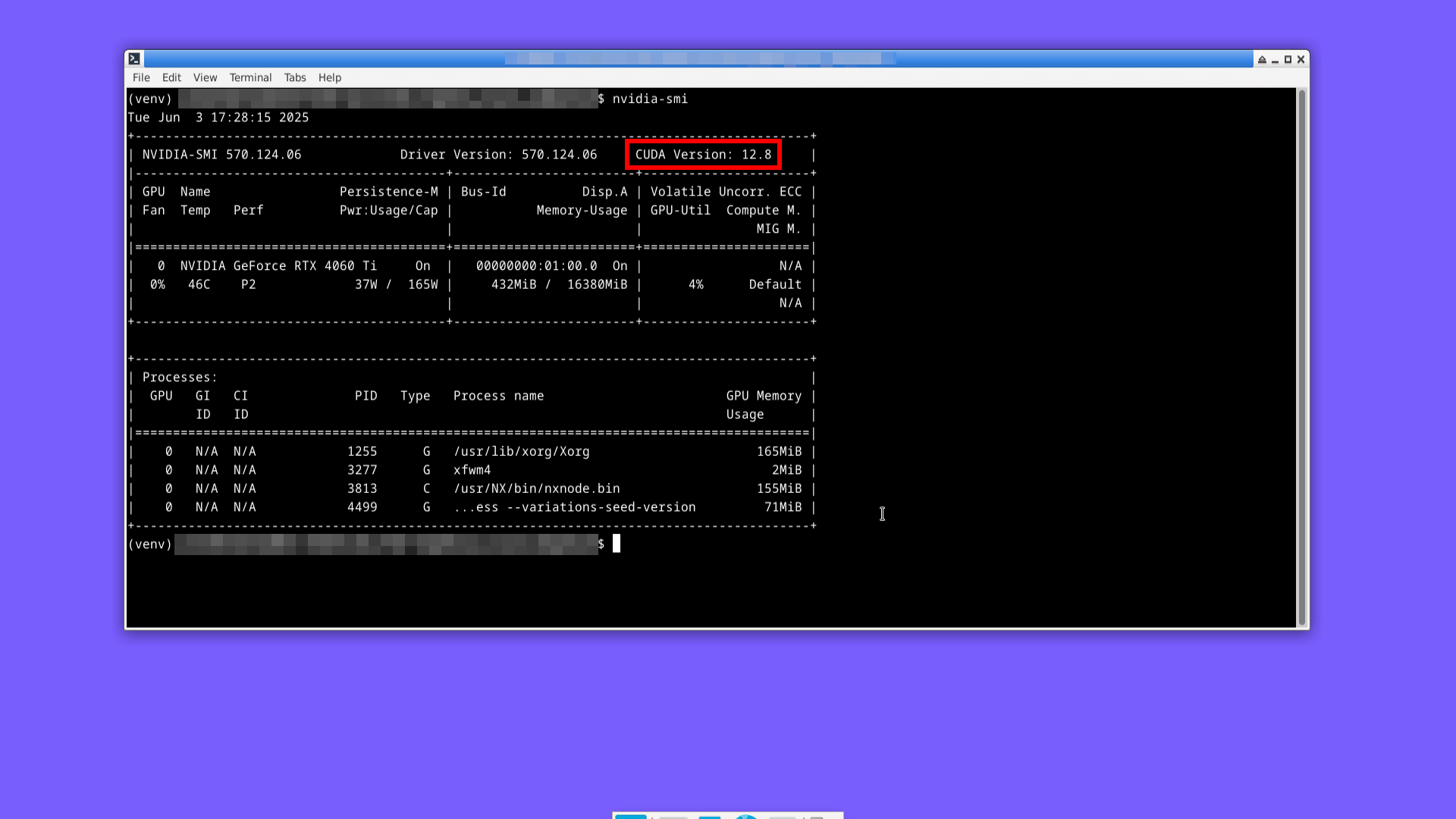
У меня CUDA версии 12.8.
Переходим на сайт PyTorch по ссылке: https://pytorch.org/get-started/locally.
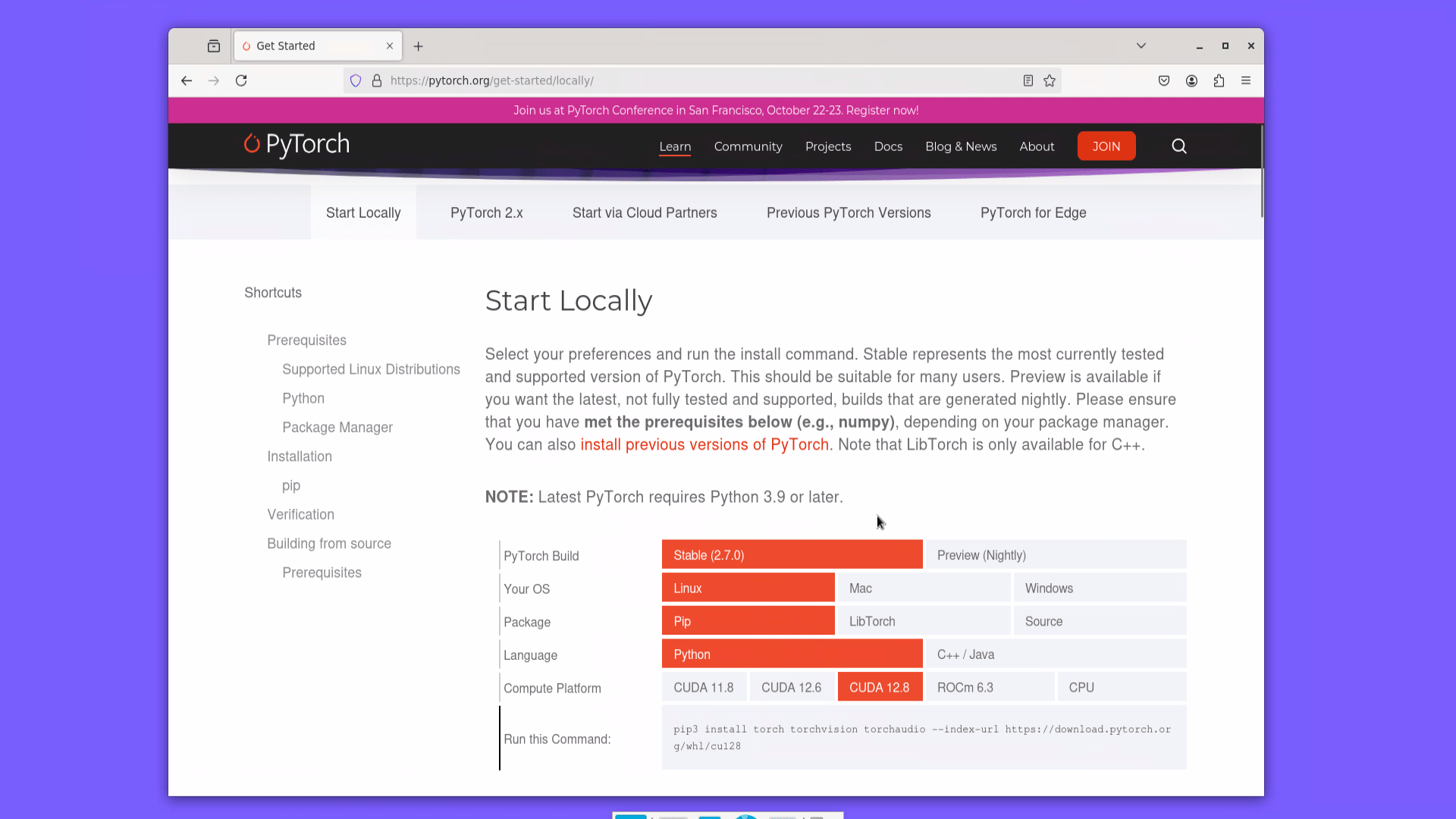
Выбираем версию CUDA и получаем команду на скачивание PyTorch. У меня получилась следующая команда:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128Установим набор инструментов NVIDIA CUDA Toolkit. Для версий CUDA 12.X переходим по ссылке: https://developer.nvidia.com/cuda-toolkit-archive и выбираем самую свежую версию NVIDIA CUDA Toolkit.
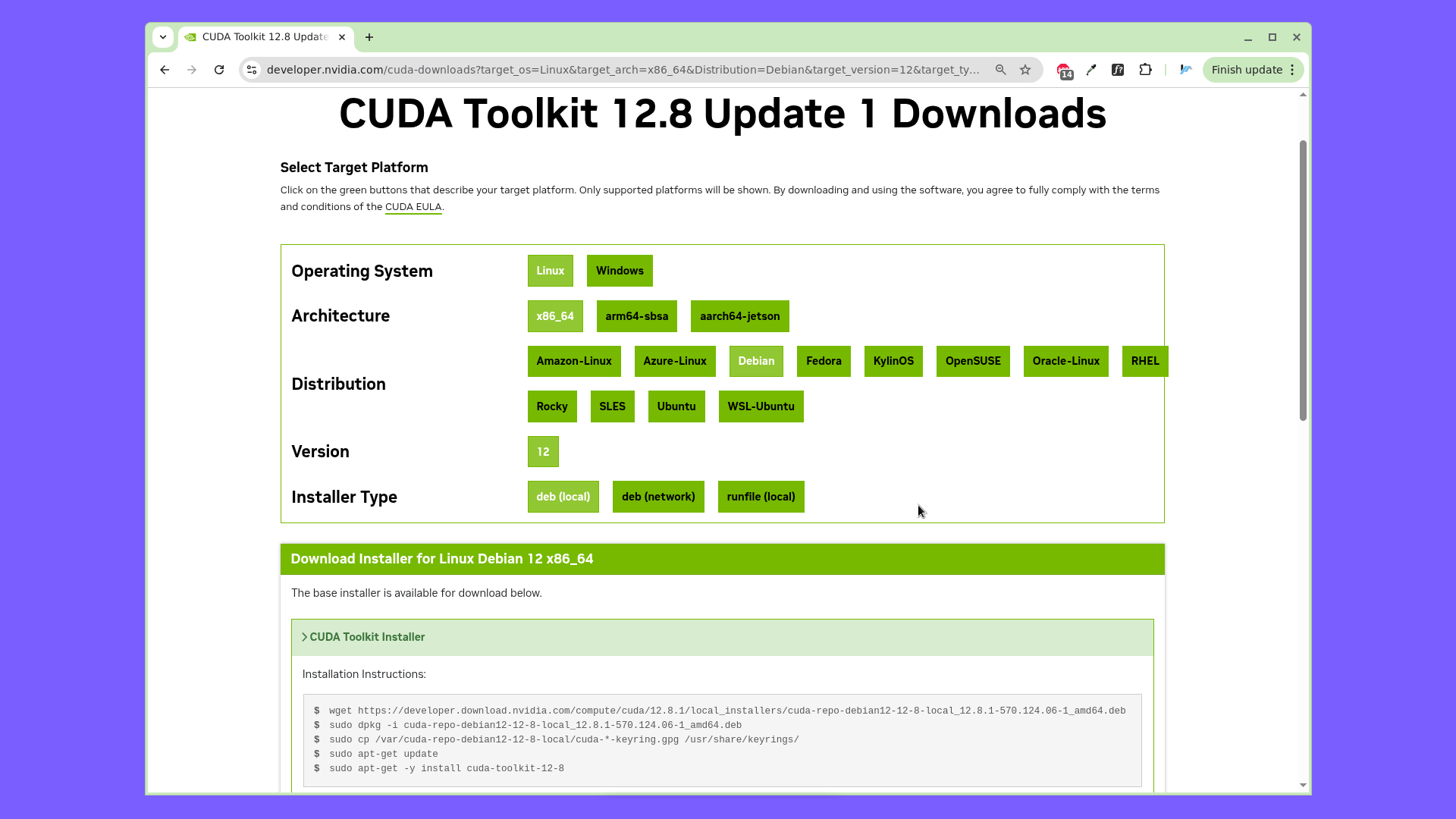
Выбираем операционную систему, дистрибутив, тип установщика. Скачиваем и устанавливаем набор инструментов согласно появивщейся инструкции. У меня в инструкции были следующие команды:
wget https://developer.download.nvidia.com/compute/cuda/12.8.1/local_installers/cuda-repo-debian12-12-8-local_12.8.1-570.124.06-1_amd64.deb
sudo dpkg -i cuda-repo-debian12-12-8-local_12.8.1-570.124.06-1_amd64.deb
sudo cp /var/cuda-repo-debian12-12-8-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-8Установим NVIDIA cuDNN — специализированную библиотеку от NVIDIA, предназначенную для ускорения работы нейронных сетей на GPU. Для версий CUDA 12.X переходим по ссылке: https://developer.nvidia.com/cudnn-archive и выбираем самую свежую версию NVIDIA cuDNN.
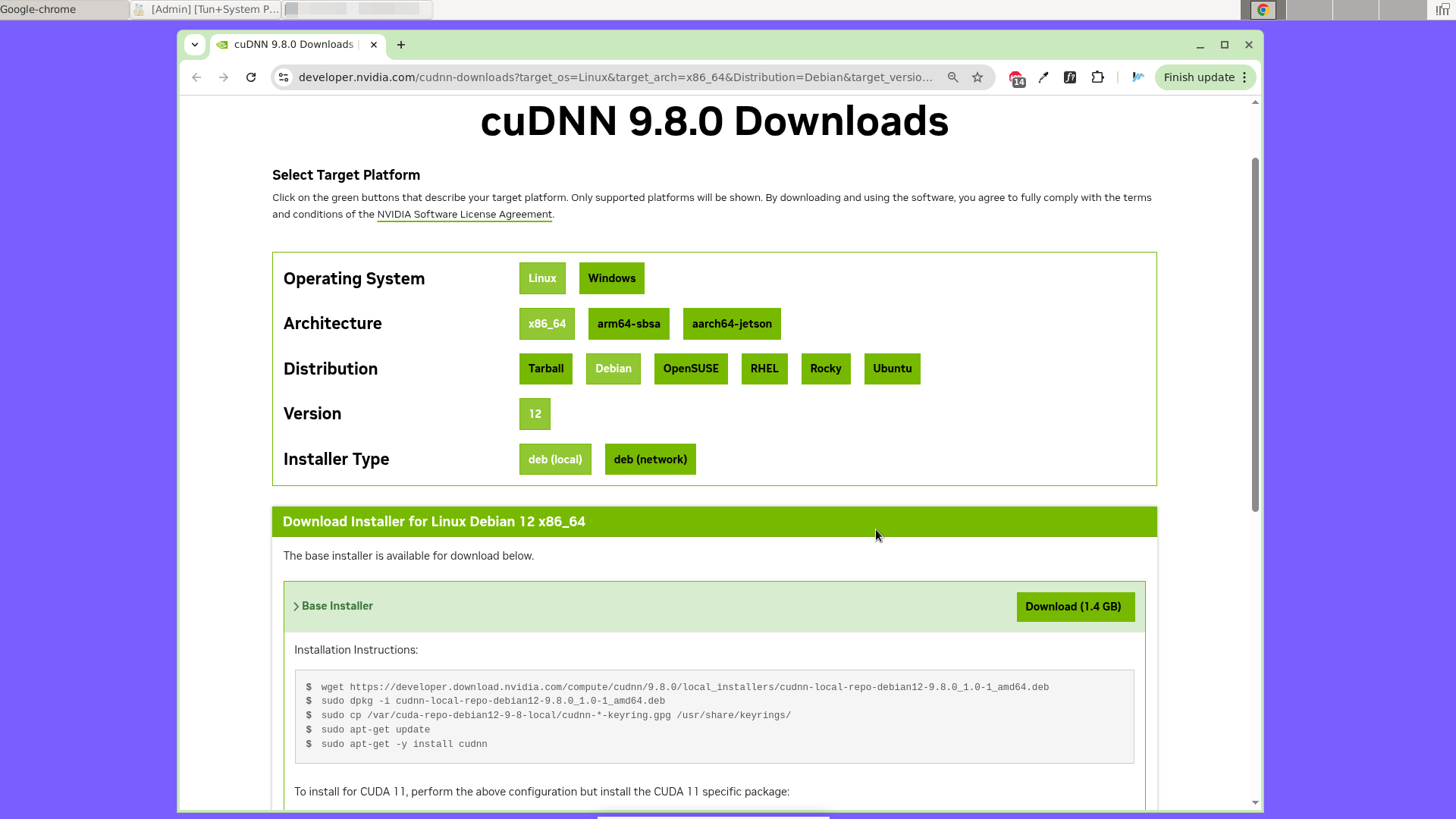
Выбираем операционную систему, дистрибутив, тип установщика. Скачиваем и устанавливаем набор инструментов согласно появивщейся инструкции. У меня в инструкции были следующие команды:
wget https://developer.download.nvidia.com/compute/cudnn/9.8.0/local_installers/cudnn-local-repo-debian12-9.8.0_1.0-1_amd64.deb
sudo dpkg -i cudnn-local-repo-debian12-9.8.0_1.0-1_amd64.deb
sudo cp /var/cuda-repo-debian12-9-8-local/cudnn-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cudnnУстанавливаем RealtimeSTT — библиотеку для распознавания речи (SST=Speech-to-Text) в реальном времени:
pip install RealtimeSTTТут мы уже можем протестировать работоспособность распознавания речи. Вот код Python-программы для этого:
from RealtimeSTT import AudioToTextRecorder
if __name__ == '__main__':
print("Wait until it says 'speak now'")
recorder = AudioToTextRecorder()
while True:
print(recorder.text())Аудиосигнал захватывается с микрофона по умолчанию, распознается речь, результат распознавания выводится в виде текста на консоль:
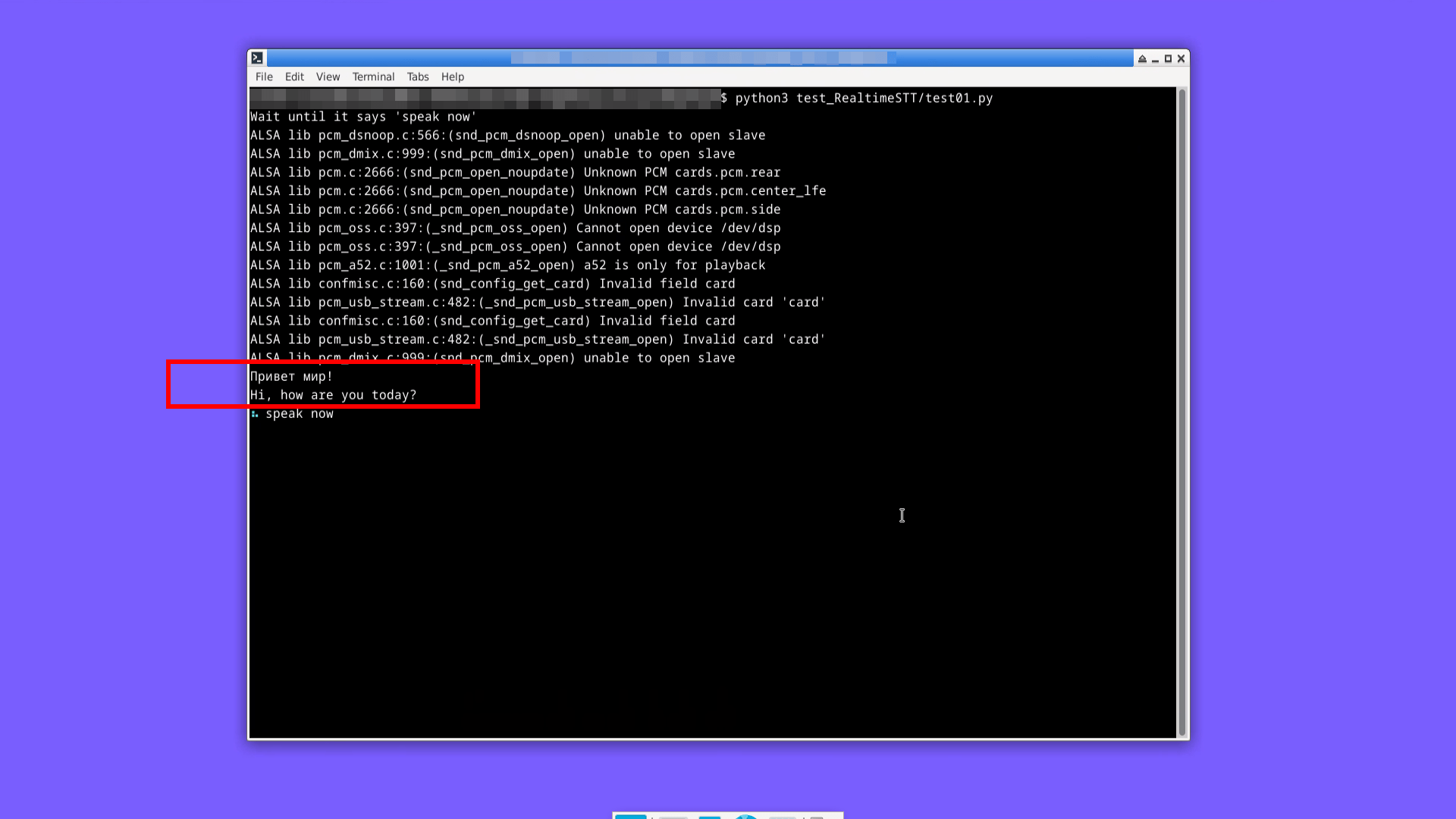
Для распознавания речи по умолчанию используется модель Faster Whisper размера tiny.
При первом обращении модель скачивается с сайта Hugging Face: https://huggingface.co/. При последующих обращениях используется скаченная модель. Директория для размещения скаченной модели: ~/.cache/huggingface/hub/.
Модель обнаружения голосовой активности
Для обнаружения голосовой активности используются: WebRTCVAD (для начального обнаружения голосовой активности) и SileroVAD (для более точного обнаружения).
При первом обращении модель SileroVAD скачивается с GitHub-репозитория: https://github.com/snakers4/silero-vad.git. При последующих обращениях используется скаченная модель. Директория для размещения скаченной модели: ~/.cache/torch/hub/snakers4_silero-vad_master/.
WebRTCVAD — это не обучаемая модель, а нативная C++-библиотека. Используется в Python через обёртку — Python-библиотеку webrtcvad-wheels. При запуске ничего не скачивает из Интернета.
Перевод с одного языка на другой
Устанавливаем Transformers — библиотеку от Hugging Face, предоставляющую доступ к современным предобученным моделям.
pip install transformers==4.51.3В команде на установку указана конкретная версия библиотеки (4.51.3), поскольку самая свежая версия библиотеки на момент написания статьи (4.52.4) валится с ошибками.
Модель машинного перевода
Для перевода с английского языка на русский язык будем использовать модель facebook/nllb-200-1.3B. Это мощная модель машинного перевода, созданная Meta (Facebook), способная переводить между 200 языков напрямую, без необходимости переводить через английский. Модель содержит 1.3 миллиарда параметров.
При первом обращении модель скачивается с сайта Hugging Face. При последующих обращениях используется скаченная модель. Директория для размещения скаченной модели: ~/.cache/huggingface/hub/.
Синтез речи
Устанавливаем RealtimeTTS — библиотеку для синтеза речи (TTS=Text-to-Speech) в реальном времени, настроенную на работу с моделью Coqui TTS.
pip install realtimetts[coqui]Модель синтеза речи
Coqui TTS — это высококачественная модель синтеза речи с локальной обработкой, не требующая Интернет. При первом обращении модель скачивается с сервера Coqui AI. При последующих обращениях используется скаченная модель. Размещается скаченная модель в поддиректории models/.
Голос для синтеза речи
Сделаем запись собственного голоса, чтобы переводчик заговорил нашем же голосом. Нужна запись со следующими параметрами:
- Частота: 22050 Гц
- Каналы: моно
- Разрядность: 16 бит
- Формат: WAV
- Длительность: ~5-30 секунд
Запускаем команду на запись голоса с требуемыми параметрами и длительностью 20 секунд:
arecord -f S16_LE -r 22050 -c 1 -d 20 -t wav irina.wavгде irina.wav — это имя выходного файла.
Готово! Голос записан.
Тест синтеза речи
Тут мы уже можем протестировать работоспособность синтеза речи. Вот код Python-программы для этого:
from RealtimeTTS import TextToAudioStream, CoquiEngine
if __name__ == '__main__':
text = "Привет, мир! "
engine = CoquiEngine(voices_path='sounds/', voice='irina', language="ru", specific_model="v2.0.3")
stream = TextToAudioStream(engine, language='ru')
stream.feed(text).play(language='ru')
print("Playout finished")
engine.shutdown()В поддиректорию sounds/ я расположила файл irina.wav, созданный на предыдущем шаге.
Синтезированная речь воспроизводится на динамике по умолчанию. Ух! Звучит очень реалистично и похожа на мой собственный голос.
Вывод звука на Bluetooth наушники
Настроим вывод синтезированной речи на Bluetooth наушники, которые не являются динамиком по умолчанию.
PortAudio по умолчанию
PyAudio — это Python-библиотека, которая предоставляет простой интерфейс для работы с PortAudio, кросс-платформенным аудио API.
Устанавливается PortAudio командой:
apt install portaudio19-devPython-библиотека PyAudio устанавливается командой:
pip install pyaudioУ меня в таком виде библиотека PyAudio не обнаруживает Bluetooth наушники. Т.е., если запустить Python-код:
import pyaudio
p = pyaudio.PyAudio()
for i in range(p.get_device_count()):
info = p.get_device_info_by_index(i)
print(f"Device {i}: {info['name']}")
то в терминале отобразятся обнаруженные устройства:
Device 0: Sound Blaster Play! 3: USB Audio (hw:0,0)
Device 1: HDA NVidia: HDMI 0 (hw:1,3)
Device 2: HDA NVidia: HDMI 1 (hw:1,7)
Device 3: HDA NVidia: HDMI 2 (hw:1,8)
Device 4: HDA NVidia: HDMI 3 (hw:1,9)
Device 5: sysdefault
Device 6: spdif
Device 7: lavrate
Device 8: samplerate
Device 9: speexrate
Device 10: pulse
Device 11: speex
Device 12: upmix
Device 13: vdownmix
Device 14: default
Bluetooth наушников среди них нет.
PortAudio с поддержкой PulseAudio
Чтобы библиотека PyAudio обнаруживала Bluetooth устройства, необходимо, чтобы в PortAudio была включена поддержка PulseAudio. Пересоберем PortAudio с поддержкой PulseAudio.
Удаляем установленный PortAudio:
apt remove portaudio19-dev libportaudio2 libportaudiocpp0Проверяем, что больше не осталось установленных пакетов, связанных с PortAudio:
apt list --installed | grep portaudioУстанавливаем:
apt install libpulse-devСкачиваем и собираем PortAudio с поддержкой PulseAudio:
git clone https://github.com/PortAudio/portaudio.gitcd portaudio./configure --with-pulseaudiomakemake installДобавляем директорию /usr/local/lib (место установки PortAudio с поддержкой PulseAudio) в переменную окружения LD_LIBRARY_PATH. Для этого под пользователем user:
echo "export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH" >> ~/.bashrcПрименяем изменения:
source ~/.bashrcsource venv/bin/activateСнова запускаем предыдущий Python-код. Все Bluetooth устройства должны обнаружиться!
Device 0: Sound Blaster Play! 3: USB Audio (hw:0,0)
Device 1: HDA NVidia: HDMI 0 (hw:1,3)
Device 2: HDA NVidia: HDMI 1 (hw:1,7)
Device 3: HDA NVidia: HDMI 2 (hw:1,8)
Device 4: HDA NVidia: HDMI 3 (hw:1,9)
Device 5: spdif
Device 6: pulse
Device 7: speex
Device 8: upmix
Device 9: vdownmix
Device 10: default
Device 11: Default Sink
Device 12: Default Source
Device 13: Sound Blaster Play! 3 Analog Stereo
Device 14: NoMachine Output
Device 15: HOCO W35 Max
Device 16: Monitor of Sound Blaster Play! 3 Analog Stereo
Device 17: Sound Blaster Play! 3 Digital Stereo (IEC958)
Device 18: Monitor of NoMachine Output
Device 19: Remapped nx_voice_out
Device 20: Monitor of HOCO W35 Max
Теперь, указав индекс устройства, мы выведем синтезированную речь на это устройство.
Небольшие правки RealtimeTTS
В файле stream_player.py из пакета RealtimeTTS закомментируем весь следующий код:
while self.audio_stream.stream.get_write_available() < frames_in_sub_chunk:
if time.time() - start_time > timeout:
print(f"Wait aborted: Timeout of {timeout}s exceeded. "
f"Buffer availability: {self.audio_stream.stream.get_write_available()}, "
f"Frames in sub-chunk: {frames_in_sub_chunk}")
break
time.sleep(0.001) # Small sleep to let the stream process audioВ файле text_to_stream.py из пакета RealtimeTTS закомментируем строку:
print("SYNTHESIS FINISHED")А в строке:
and len(self.char_iter.items) > 1единицу меняем на ноль.
Полный код переводчика
from RealtimeSTT import AudioToTextRecorder
import torch
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from RealtimeTTS import TextToAudioStream, CoquiEngine
import pyaudio
import logging
if __name__ == '__main__':
logging.basicConfig(level=logging.ERROR, force=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_name = "facebook/nllb-200-1.3B"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name).to(device)
tokenizer.src_lang = "eng_Latn"
forced_bos_token_id = tokenizer.convert_tokens_to_ids("rus_Cyrl")
def translate_text(text):
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=512).to(device)
translated_tokens = model.generate(**inputs, forced_bos_token_id=forced_bos_token_id, max_length=512)
translation = tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)
return translation[0]
print("System initializing, please wait...")
def find_bluetooth_device_index(target_name="HOCO W35 Max", exclude_name="Monitor"):
p = pyaudio.PyAudio()
for i in range(p.get_device_count()):
info = p.get_device_info_by_index(i)
name = info['name']
if target_name in name and exclude_name not in name:
return i
return -1
index = find_bluetooth_device_index()
if index == -1:
print("Blutooth device is not found")
exit(0)
engine = CoquiEngine(voices_path='sounds/', voice='irina', language="ru", specific_model="v2.0.3", speed=1.2)
stream = TextToAudioStream(engine, language='ru', output_device_index=index)
recorder = None
end_of_sentence_detection_pause = 0.35
unknown_sentence_detection_pause = 0.7
mid_sentence_detection_pause = 2.0
prev_text = ""
def preprocess_text(text):
text = text.lstrip()
if text.startswith("..."):
text = text[3:]
text = text.lstrip()
if text:
text = text[0].upper() + text[1:]
return text
def text_detected(text):
global prev_text, recorder
sentence_end_marks = ['.', '!', '?']
text = preprocess_text(text)
if text.endswith("..."):
recorder.post_speech_silence_duration = mid_sentence_detection_pause
elif text and text[-1] in sentence_end_marks and prev_text and prev_text[-1] in sentence_end_marks:
recorder.post_speech_silence_duration = end_of_sentence_detection_pause
else:
recorder.post_speech_silence_duration = unknown_sentence_detection_pause
prev_text = text
def process_text(text):
text = preprocess_text(text)
text = text.rstrip()
if text.endswith("..."):
text = text[:-2]
if not text:
return
try:
translated_text = translate_text(text)
print(f"{translated_text}")
stream.feed(translated_text).play_async(language='ru', fast_sentence_fragment_allsentences=True)
except Exception as e:
print("Exception")
recorder_config = {
'spinner': False,
'model': 'large-v2',
'download_root': None, # default download root location (~/.cache/huggingface/hub/)
'realtime_model_type': 'tiny.en',
'language': 'en',
'webrtc_sensitivity': 3,
'post_speech_silence_duration': unknown_sentence_detection_pause,
'min_length_of_recording': 1.1,
'min_gap_between_recordings': 0,
'enable_realtime_transcription': False,
'realtime_processing_pause': 0.02,
'on_realtime_transcription_update': text_detected,
'silero_deactivity_detection': True, # Enables the Silero model for end-of-speech detection
'early_transcription_on_silence': 0,
'beam_size': 5,
'beam_size_realtime': 3,
'no_log_file': True,
}
recorder = AudioToTextRecorder(**recorder_config)
print("\nSay something...\n")
try:
while True:
recorder.text(process_text)
except KeyboardInterrupt:
print("Exiting...")
engine.shutdown()
exit(0)Потребляемые ресурсы
Использование графического процессора GPU, видеопамяти, а также список процессов, использующих GPU, удобно смотреть в терминальном приложении nvtop. Это монитор ресурсов в реальном времени для видеокарт NVIDIA.
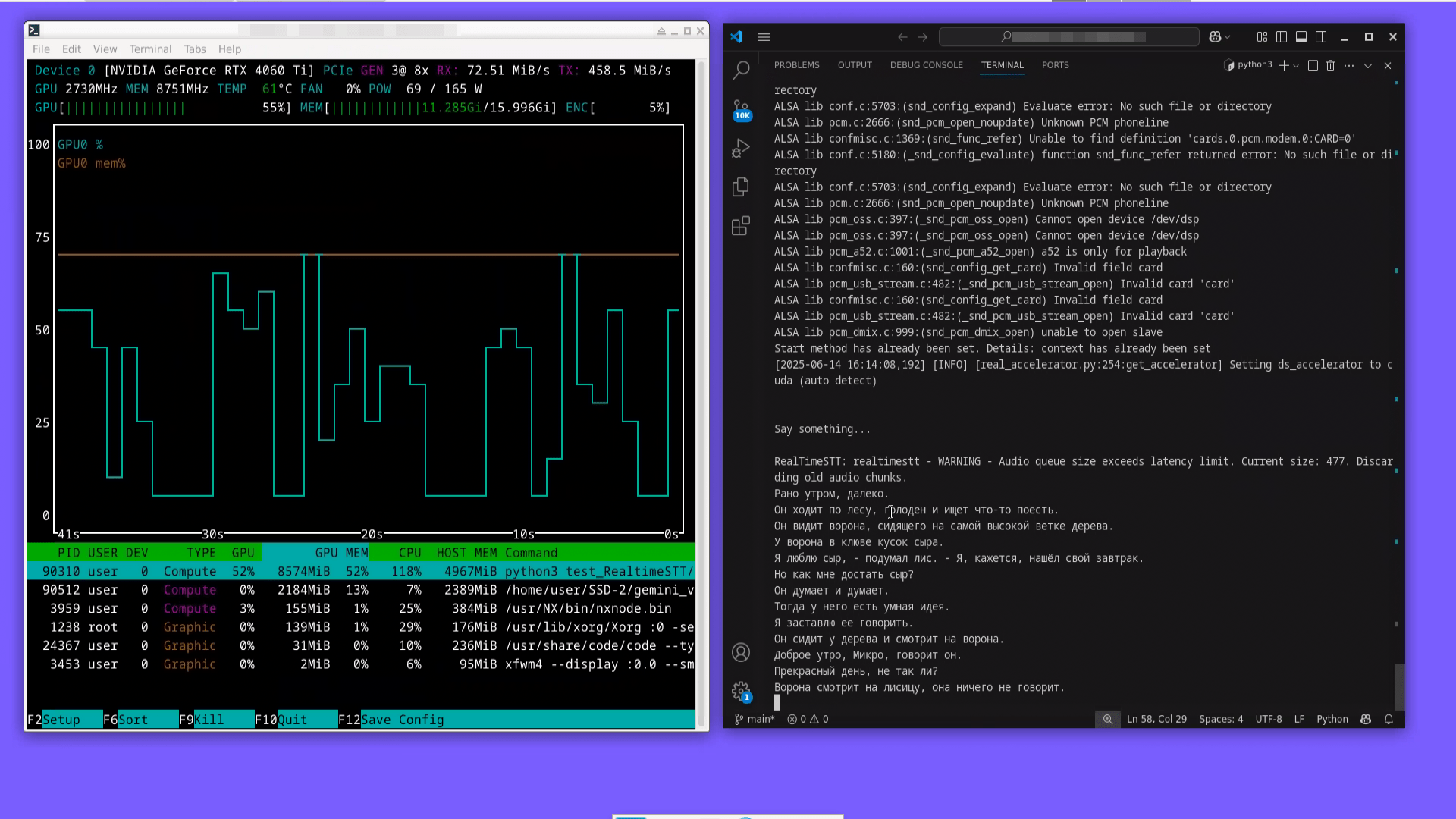
Вывод
Полный код бесплатного, оффлайн переводчика в реальном времени с английского языка на русский получился чуть более 100 строк. Работает очень круто. Я довольна!
Все вопросы жду в комментариях под статьей.
Комментарии